
Selecting a proper technology for a new project is always a stressful event. We need to find something that will fit all existing requirements, does not restrict further growth, allows to achieve necessary performance, does not put a heavy operational burden, etc. It’s only natural that selecting a database can be tricky.
In this article, I would like to describe DynamoDB database created by AWS. My goal is to give you enough knowledge so you would be able to answer a simple question: “Should I use DynamoDB in my next project?”. I will describe in what cases DynamoDB can be used efficiently and what pitfalls to avoid. I hope this will help you to make your life easier.
This article will start with a general overview of DynamoDB; then I will show how to structure data for DynamoDB and what options do you have to work with DynamoDB. The article will finish with a rundown of some advanced features of DynamoDB.
What is DynamoDB
Let’s start with what is AWS DynamoDB. DynamoDB is a NoSQL, key-value/document-oriented database. As a key-value database, it allows storing an item with an id and then get an item back. As a document-oriented database, it allows storing complex nested documents.
DynamoDB is a serverless database, meaning that when you work with it you do not need to worry about individual machines. In fact, there is even no way to find out how many machines Amazon is using to serve your data. Instead of working with individual servers you need to specify how many read and write requests your database should process.
On the one hand, this allows Amazon to provide a predictable low latency which is according to many sources is less than 10 ms if a request is coming from an EC2 host from the same AWS region. The latency can be even lower (<1 ms) if you enable cache for DynamoDB (more on this in the later section).
On the other hand specifying a number of requests instead of a number of servers allows you to concentrate on the business value of the database and not on the implementation details. If you have an estimate of how many requests you need to process, all you need to do is to specify a number in AWS console or perform an API request. This can’t be simpler.
The price that you pay for using DynamoDB is primarily determined by the provisioned capacity for your DynamoDB database. The higher it is, the higher the monthly bill is. DynamoDB also provides a small amount so-called “burst capacity” which can be used for a short period of time to read or write more data that your provisioned capacity allows. If you’ve consumed it and still read or write more data, DynamoDB will return a ProvisionedThroughputExceededException, and you need either to retry an operation or provision more capacity.
In addition to these major features there are few other reasons why you might consider DynamoDB:
- Massive scale – just as other AWS services DynamoDB can work on a massive scale. Many other companies such as Airbnb, Lyft, and Duolingo are using DynamoDB in production.
- Low operational overhead – you still need to do some operational tasks, such as, ensure that you have enough provisioned capacity, but most of the operational load is taken by the AWS team.
- Reliable – despite few outages DynamoDB has a proven track of being rock-solid database solution. Also, all data that is written to DynamoDB is replicated to three different location.
- Schemaless – just as many other NoSQL databases DynamoDB does not impose strict schema allowing more flexibility.
- Simple API – DynamoDB API is very straightforward. Overall it has less than twenty methods an only a handful of them is related to writing and reading data.
- Autoscaling – it is pretty straightforward to scale DynamoDB database up or down. All you need to do is to enable autoscaling on a particular table, and AWS will automatically increase or decrease provisioned capacity depending on current load. Alternatively, you can perform the UpdateTable API call and change the provisioned capacity.
- Integration with other AWS services – DynamoDB is one of the core AWS services and has good integration with other services. You can use it together with CloudSearch to enable full-text search, perform data analytics with AWS EMR, back up data with AWS Data Pipeline, etc.
Data model in DynamoDB
Now let’s take a look at how to store data in DynamoDB. Data in DynamoDB is separated into tables. When you create a table, you need to decide on the key type that your table will have. DynamoDB has two types of keys and when you select a key type and you can’t change once it is selected:
- Simple key – in this case, you need to identify what attribute in the table contains a key. This key is called a partition key. With this key type, DynamoDB does not give you a lot of flexibility and the only operation that you can do efficiently is to store an element with a key and get an element by a key back.
- Composite key – in this case, you need to specify two key values which are called partition key and a sort key. As in the previous case, you can get an item by key, but you can also query this data in a more elaborate way. For example, you can get all items with the same partition key, sort result data by the value of the sort key, filter items using the value of the sort key, etc. The pair of partition/sort should be unique for each item.
Let’s take a look at some examples of using simple and composite keys. For example, if we want to store a table with users in our database we could use a table with a simple key and store it like this:

With this table, the only operation that we can perform efficiently is to get a user by id.
Composite keys allow more flexibility. For example, we could define a table with a composite that stores forum messages and select user id as a partition key and timestamp as a sort key:

This structure would allow performing more complex queries like:
- Get all forum posts written by user with a specified id
- Get all forum posts written by a specified user sorted by time (we can do this because we have the sort key)
- Get all forum posts that were written in a specified time interval (we can do this because we can specify filtering expression on a sort key)
Notice that in this case, you can only query data for a specified partition key. If you want to search for items across partition keys you need to use the scan operation. It allows finding all items in a table that match a specified filter expression. This operation is less restrictive than the first two, but it does not exploit any knowledge about where data is stored in DynamoDB and ends up scanning the whole table.
You should try to use the scan operation as little as possible. While it allows much more flexibility, it is significantly slower and consumes more provisioned capacity. If you are extensively relying on scanning big tables, you won’t achieve high performance and will have to provision more capacity and hence pay more money.
Consistency in DynamoDB
As with many other NoSQL databases, you can select consistency level when you perform operations with DynamoDB. DynamoDB stores three copies of each item and when you write data to DynamoDB it only acknowledges a write after two copies out of three were updated. The third copy is updated later.
When you read data from DynamoDB, you have two options. You can either use strong consistency and in this DynamoDB will read data from two copies and return the latest data, or you can select eventual consistency and in this case, DynamoDB will only read data from one copy at random, and may return stale data.
Indexes
Simple key and composite key model is quite restrictive and is not enough to support complex use cases. To help with that DynamoDB supports two index types:
- Local secondary index – is very similar to composite key and is used to define additional sort order or to filter items by a different criteria. The main difference from a composite key is that a pair of a partition/sort key should be unique, but a pair of partition/secondary index should not be unique.
- Global secondary index – this allows using a different partition key for your data. You can use a global secondary index if you want to get an item from a table by one of two ids, for example, a book in an online shop can have two ids: ISBN-10 and ISBN-13. As with regular tables, global secondary indexes can have simple and composite keys.
Internally, global secondary index is simply a copy of your original data in a separate DynamoDB table with a different key. When an item is written into a table with a global secondary index, DynamoDB copies data in the background. Because of this writing data into a global secondary is always eventually consistent.
With DynamoDB you can create up to five local secondary indexes and up to five global secondary indexes per table.
Complex data
All examples so far presented data in table format but DynamoDB also supports complex data types. In addition to simple data types like numbers and strings DynamoDB supports these types:
- Nested object – a value of an attribute in DynamoDB can be a complex nested object
- Set – a set of numbers, strings, or binary values
- List – a untyped list that can contain any values
Programmatic access
If you want to access DynamoDB,f you have two main options: low-level API and DynamoDB mapper. All communication with DynamoDB is performed via HTTP. To read data, there are just four methods:
- GetItem – get a single item by id from a database
- BatchGetItem – get several items by id in one call
- Query – query a composite key or an index
- Scan – scan through a table
And there are just four methods to change data in DynamoDB:
- PutItem – write a new item to a table
- BatchWriteItem – write multiple items to a table
- UpdateItem – update some fields in a specified item
- DeleteItem – remove an item by id
All methods work on a table level. There are no methods that work across different tables.
The low-level API is a thin wrapper over these HTTP methods. It is verbose and cumbersome to use. For example, to get a single item from a DynamoDB table you need write that much code:
// Create DynamoDB client
AmazonDynamoDB client = AmazonDynamoDBClientBuilder.standard().build();
// Create a composite key
HashMap<String, AttributeValue> key = new HashMap<>();
key.put(”UserId”, new AttributeValue()
.withN(”1”));
key.put(”Timestamp”,new AttributeValue().withN(“1498928631”));
// Create a request object
GetItemRequest request = new GetItemRequest()
.withTableName(”ForumMessages”)
.withKey(key);
// Perform API request
GetItemResult result = client.getItem(request);
// Get attribute from the result item
AttributeValue year = result.getItem().get(”Message");
// Get string value
String message = attributeValue.getS();
The code is pretty straightforward. First, we create a key to get an item by a key, then as with other AWS API methods we create a request object and perform a request. The example is in Java, but API clients for AWS exist for other languages such as Python, .NET platform, and JavaScript.
Now you may be wondering if there is a library that will help to avoid all this massive amount boilerplate code. And in fact, AWS implemented a high-level library for this called DynamoDB mapper. To use it you first need to define a structure of your data similarly to how you define it with ORM frameworks:
// Specify table name
@DynamoDBTable(tableName=“ForumUsers”)
public class User {
// "UserId" attribute is a key
@DynamoDBHashKey(attributeName=“UserId”)
public int getUserId() {
return userId;
}
// Map this value to the "Name" attribute
@DynamoDBAttribute(attributeName = ”Name”)
public int getName() {
return name;
}
}
Now accessing data in DynamoDB is much simpler. All we need to do to is to create an instance of the DynamoDBMapper and call the load method:
// Create DynamoDB client (just as in the previous example)
AmazonDynamoDB client = AmazonDynamoDBClientBuilder.standard().build();
// Create DynamoDB mappper
DynamoDBMapper mapper = new DynamoDBMapper(client);
// Create a key instance
User key = new User();
key.setUserId(1);
// Get item by keys
User result = mapper.load(key);
Notice that now to specify a key of an item we can use a Java POJO class and not a HashMap instance as in the previous case.
Unless you need to access some nitty-gritty details of DynamoDB or need to implement a custom way of doing things I recommend to use DynamoDB mapper and only to use low-level API if necessary. Examples here were provided in Java, but there are also DynamoDB mapper implementations for other languages like .NET platform and Python.
You can also use unofficial libraries to access DynamoDB. For example, if you are using Spring you can consider using Amazon DynamoDB module for Spring Data.
Advanced features
All features described so far are core DynamoDB features, but it also has some additional more advanced features that you can use to build complex applications. In this section, I’ll provide a short list of what these features are and what you can use them for.
Optimistic locking
A common problem in a distributed systems is when different actors are stepping on each other toes while performing operations in parallel. A common example is when two different processes are trying to update the same item in a database. In this case, a second update can override data written by the first update.
To solve this problem, DynamoDB allows specifying a condition for performing an update. If a condition is satisfied, new data is written, otherwise, DynamoDB will return an error.
A common way to use this feature that is implemented in DynamoDBMapper is to maintain a version field with an item and increment it on every update. If a version was not changed a process can write new data. Otherwise, it will have to re-read data and try to perform the operation again.
This technique is also called optimistic locking and is similar to the compare-and-swap operation that is used to implement lock-free data structures.
Transactions
While DynamoDB does not have built-in support for transactions, AWS has implemented a Java library that implements transactions on top of existing DynamoDB features. A detailed design is described here, but in the nutshell when you perform an operation with the DynamoDB transaction library it stores a list of performed operations into a separate table and on commit it applies stored operations.
Since the library is open sourced there is nothing that prevents developers from implementing a similar solution for other languages, but it seems currently DynamoDB transaction support is only implemented for Java.
Time to live
Not all data that you store in DynamoDB should be stored forever. Older data can be moved to a cheaper data storage, like S3, or simply removed. To automatically delete old data DynamoDB implements the time-to-live feature which allows specifying an attribute that stores a timestamp when an item should be removed. DynamoDB tracks expired items and removes them for no extra cost.
DynamoDB Streams
Another powerful DynamoDB feature is DynamoDB streams. If it is enabled it allows reading an immutable, ordered stream of updates to a DynamoDB table. An item is written to a stream after an update is performed and allow to react to changes to DynamoDB. This is a crucial feature if you need to implement one of the following use-cases:
- Cross-region replication – you may want to store a copy of your data in a separate region to keep it closer to your users or to have a back-up of your data. To implement it you can read a DynamoDB stream and replay update operations in a second database.
- Aggregated table – DynamoDB model might not suit some of the queries you need to perform. For example, if you need to group by data, DynamoDB does not support it out of the box. To implement this feature, you may read DynamoDB update stream and maintain an aggregated table that fits DynamoDB model and allows efficient queries.
- Keep data in sync – in many cases, you need to maintain a copy of your data in a different datastore such as cache or CloudSearch. DynamoDB streams is an immense help for that. Since a record in DynamoDB stream appears only if data was stored in DynamoDB.
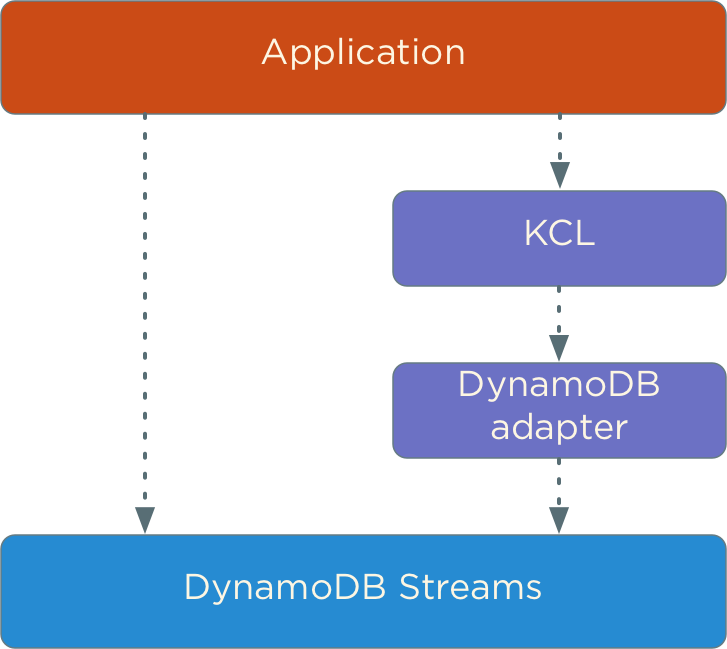
DynamoDB streams implementation is very similar to another AWS services called Kinesis. They both have similar API and to read data from any of the systems you can use Kinesis Client Library (KCL) that provides a high-level interface for reading data from a Kinesis or DynamoDB stream. Keep in mind that DynamoDB streams API and Kinesis API are slightly different, so you need to use an adapter to use KCL with DynamoDB.
DynamoDB accelerator (DAX)
As with every other database, it can be beneficial to use cache if you use DynamoDB. Unfortunately, it may be tricky to maintain cache consistency. If you use a caching solution like ElastiCache, it may be a good idea to utilize DynamoDB stream to maintain a copy of your data in a cache, but recently DynamoDB has introduced a new feature called DynamoDB accelerator.
DAX is write-through caching layer for DynamoDB. It has exactly the same API as DynamoDB, and if you’ve enabled it, you are supposed to read and write to DynamoDB through it. DAX keeps track of what data was written to DynamoDB and only stores it if a write was acknowledged by DynamoDB.
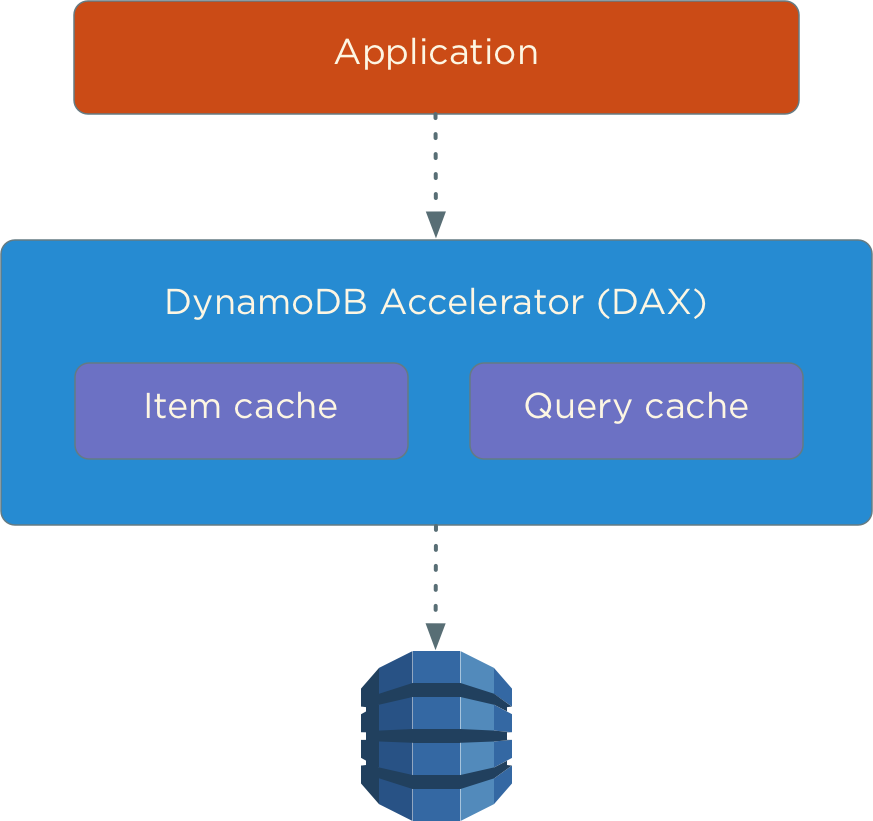
One of the key benefits of using DAX is that it has a sub-millisecond latency which may be especially important if you have strict SLAs.
Conclusions
DynamoDB is a great database. It has a rich feature set, predictable low latency, and almost no operational load. The key to using it efficiently is to understand its data model and to check if you can fit your data in DynamoDB. Remember, to achieve the stellar performance you need to use queries as much as possible and try to avoid scans operations.
This was an introductory article to DynamoDB, and I will write more, so stay tuned. In the meantime, you can take a look at my deep dive DynamoDB course. You can watch the preview for the course here.
Share this: